简单scrapy爬虫实例
流程分析
抓取内容:网站课程
页面:https://edu.hellobi.com
数据:课程名、课程链接及学习人数
观察页面url变化规律以及页面源代码帮助我们获取所有数据
1、scrapy爬虫的创建
在pycharm的Terminal中输入以下命令:
创建scrapy项目:scrapy startproject ts
进入到项目目录中:cd first
创建一个新的spider:scrapy genspider -t basic lesson hellobi.com
2、scrapy爬虫代码编写
2.1items文件编写
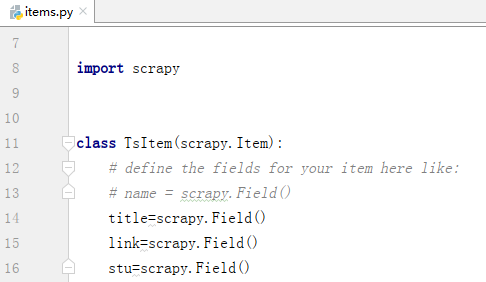
在items.py文件中定义自己要抓取的数据,我们要爬取天善智能网站的课程、课程链接和学习人数,需要这三者的数据,所以此时创建item的三个类。
2.2编写spider文件(lesson.py)
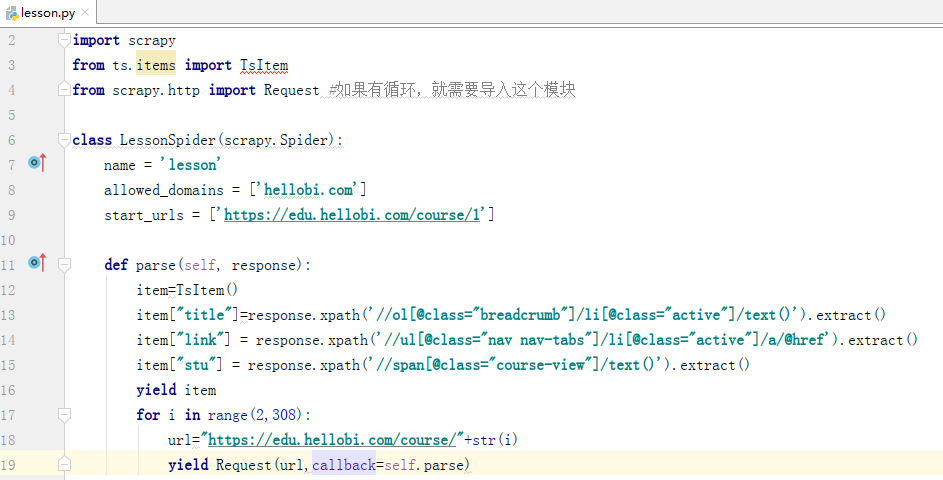
由于要提取该网站所有课程的消息,需要构造了所有的课程url。此时观察观察多个url,找出其中url变化的规律,以此来构造所有的url。由于每个课程都需要包含课程名、课程链接以及学习人数,所有设置相应的xpath,分别匹配item的三个类。
2.3修改pipeline.py的内容:
将爬取到的数据写入“F:/天善课程爬取/1.txt”中。

2.4修改settings.py文件,配置pipeline:

3、总结
至此,爬虫就全部编写完成了,在scrapy中xpath很重要,如果xpath提取错误的话,可能会造成许多错误。另外在输出和写入文件时也要注意,不然也会有错误发生。在程序的最后一定要关闭文件,不然最后打开文件的内容为空。